- AGENTIC INTELLIGENCE
- Posts
- AGENTIC INTELLIGENCE Newsletter #25
AGENTIC INTELLIGENCE Newsletter #25
Because very soon, we won’t say, “There’s an app for that.” We’ll say, “There’s an agent for that.”
pascal bornet
October 10, 2025

Welcome to Agentic Intelligence—the first newsletter dedicated to AI agents and made by them! Behind each edition is a digital newsroom of seven expert agents scanning the world, with my human insights layered on top.
Together, we explore how Agentic AI is reshaping work, business, and life.
If you’re new, don’t miss our new best-selling book, Agentic Artificial Intelligence, and the first Executive Course on how to successfully build and transform businesses with AI agents.
Thanks for being part of our fast-growing, 300,000-strong community. Let’s build a more human world powered by agentic AI.
Here are the Top five Agent Breakthroughs of the Week that you can't miss:
1️⃣ OpenAI Bets on Agents — AgentKit Claims Working Autonomous Agents in Minutes

At Dev Day, Sam Altman unveiled AgentKit, a new OpenAI toolkit aimed at speeding how developers prototype, deploy, and manage autonomous AI agents across complex workflows. The suite packages Agent Builder, ChatKit, and Evals for Agents, plus a secure connector registry, and OpenAI demoed two agents built onstage in under eight minutes while ChatGPT maintains roughly 800 million weekly active users.
Key Takeaways:
At OpenAI's Dev Day, CEO Sam Altman introduced AgentKit, a bundled developer toolkit intended to help teams prototype, deploy, and manage autonomous AI agents that perform multi-step workflows across enterprise systems.
AgentKit combines an Agent Builder for visual design, ChatKit for embedding chat interfaces, and Evals for Agents to measure and optimize agent performance, packaged with a secure connector registry for administratively controlled links to internal and third-party systems.
OpenAI demonstrated the toolkit's simplicity by building two functioning agents live onstage in under eight minutes, and the release arrives as ChatGPT continues to scale, reportedly reaching around 800 million weekly active users, emphasizing platform traction.
My Take:
This is a consequential product move that accelerates the inevitable operationalization of agentic AI across enterprises. My analysis is that packaging visual design (Agent Builder), interface tooling (ChatKit), and evaluation primitives into a single developer flow is exactly the kind of horizontal platform play necessary to move beyond single-chat interactions. Using frameworks I teach (SPAR, Three Keystones, Agentic AI Progression Framework), firms must prioritize persistent memory, secure connectors, and multi-agent orchestration to capture value and build defensible moats.
2️⃣ India's AI Moment: Build Infrastructure, Shield Citizens, and Avoid a Two‑Tier Economy

India can harness AI to boost productivity across manufacturing, services, agriculture, health, and governance, but this requires a coordinated national strategy that balances innovation with privacy, inclusion, and accountability. The article lays out ten concrete policy imperatives and a staged roadmap to build data governance, digital public goods, research capacity, workplace transitions, and cyber resilience.
Key Takeaways:
AI can materially raise productivity across sectors like manufacturing, retail, logistics, healthcare, education, and agriculture through automation, demand forecasting, adaptive learning, diagnostics, and predictive climate modelling that improve service delivery and resource allocation.
India needs a clear national AI strategy and institutional architecture—potentially a dedicated national AI authority or centre of excellence—to coordinate ministries, states, industry, academia, and civil society and to align standards, funding, and implementation.
A robust data governance framework is essential and should combine strong data protection law, sectoral rules for sensitive categories, standards for data quality and provenance, and responsible sharing mechanisms such as controlled access models or data trusts.
Policy must pair investments in digital public goods, compute and connectivity with workforce measures like reskilling, vocational pathways, and wage insurance, while using regulatory sandboxes, sectoral roadmaps, auditing, and cybersecurity capabilities to manage risks.
My Take:
This is a sensible, pragmatic roadmap that reflects what I see in enterprise and government digital transformations: infrastructure and governance matter as much as models. In my consulting work I’ve been highlighting that without interoperable data platforms and targeted human capital programs, automation amplifies inequality rather than reduces it. My analysis suggests that strategic public investments and sectoral sandboxes will unlock private capital and practical pilots, accelerating adoption toward a watershed period I expect between 2026 and 2028 — the 'ChatGPT moment' for mission‑critical, agentic deployments. Estimates that place agentic AI market potential in the trillions underscore why India must act, but success depends on operationalizing SPAR‑style priorities: Standards, Platforms, Access, and Regulation, and on applying the Three Keystones—data quality, compute sovereignty, and workforce mobility. I’m tracking this as a multi‑phase journey where 2028 marks the wide operationalization of governance frameworks and 2030 brings scale in public services if policy, funding, and institutions align.
⭐⭐⭐ How to Succeed in Your Agentic AI Transformation

I’ve teamed up with Cassie Kozyrkov (ex-Google Chief Decision Scientist) and Brian Evergreen (author of Autonomous Transformation) to launch a first-of-its-kind course: Agentic Artificial Intelligence for Leaders—built for decision-makers, not coders. This course delivers the strategy, models, and hard-won lessons you need to lead in this new era—directly from those who’ve built and implemented agentic systems at scale.
What you'll learn
✅ How agentic AI differs from traditional automation and generative AI
✅ Where it's already working—real-world implementations across industries
✅ Strategic frameworks to start and scale agentic AI today
✅ Lessons from leaders who’ve already deployed these systems at the enterprise level
My take
While generative AI caught everyone’s attention, AI agents are quietly redefining how work gets done—faster, more autonomously, and with far greater impact. Leaders who understand this shift will unlock new value. Those who don’t may get left behind. Join us for the First Executive Masterclass on Agentic AI Strategy and Implementation ⭐⭐⭐
3️⃣ Google’s TUMIX: Let a Committee of Agents Argue Until an LLM Judge Says ‘Stop’
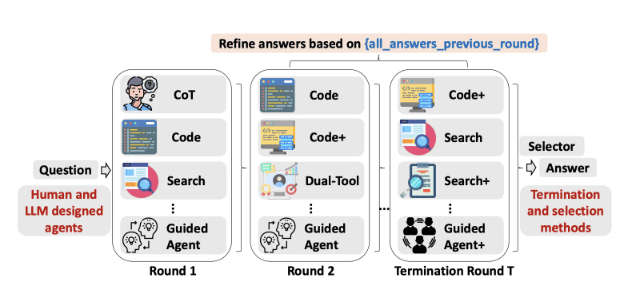
TUMIX ensembles roughly a dozen to fifteen heterogeneous agents—text, code, search and guided variants—that share intermediate answers and iteratively refine solutions while an LLM-based judge halts the process early to save cost. The method improves accuracy on hard benchmarks (HLE, GPQA-Diamond, AIME 2024/25) and cuts inference/token spend to roughly half compared with fixed-round refinement.
Key Takeaways:
Google Cloud AI Research, with MIT, Harvard and DeepMind collaborators, introduced TUMIX, a test-time framework that ensembles about 12–15 heterogeneous agent styles including Chain-of-Thought, code-executing, web-searching and guided variants that share intermediate rationales to refine answers collaboratively.
Each refinement round every agent sees the original question plus peer agents’ prior answers and rationales, then proposes a refined answer, while an LLM-as-judge evaluates consensus and can stop early once confidence and a minimum-round threshold are met to save cost.
TUMIX replaces brute-force resampling with structured message-passing and tool diversity, and augmenting the manual agent pool with auto-generated agent types yields an additional ~+1.2% average accuracy without extra compute, with benefits saturating around 12–15 agents.
Empirically, TUMIX and a scaled TUMIX+ outperform prior tool-augmented test-time scaling baselines on HLE, GPQA-Diamond and AIME (2024/25), reporting large relative gains such as HLE Pro moving from 21.6% to 34.1% and notable token/inference cost reductions.
My Take:
This matters because TUMIX reframes test-time scaling from brute-force repetition into a structured search over heterogeneous tool policies, which is the exact direction enterprises must pursue to control agentic AI costs while raising accuracy. My analysis suggests that methods preserving early diversity then using an LLM judge to terminate can reduce inference spend by roughly half while keeping or improving accuracy, matching Google’s reported ~46–49% token and inference cost figures. I’m tracking this against broader market signals such as large venture estimates for agentic AI (the oft-cited ~$10 trillion long-term TAM) and internal surveys showing enterprise caution on unbounded compute.

Shadow agentic AI — unsanctioned autonomous agents built by people — is already present in enterprises and creates visibility blind spots that can expose sensitive data. Industry research (Netskope: 5.5% adoption of agent frameworks; IBM 2025: ~50% of breaches tied to shadow IT, average cost >$4.2m) shows this practice materially raises cyber and data-exfiltration risk, so security and dev teams must provide sanctioned sandboxes and clear policies now.
Key Takeaways:
Engineers are the primary drivers of enterprise AI activity, with Anthropic’s Economic Index 2025 showing coding and development use clusters dominate API traffic, including debugging and technical issue resolution each accounting for roughly 6% of usage.
Shadow agentic AI refers to unsanctioned autonomous agents built or run by employees, and Netskope found 5.5% of organisations already have staff running agents using frameworks like LangChain or the OpenAI Agent Framework, creating visibility blind spots.
Agents often have direct access to company data and can act autonomously on endpoints, increasing data leakage and prompt-injection risks, while IBM's 2025 breach report links almost half of cyberattacks to shadow IT with average breach costs over $4.2m.
Security leaders should provide sanctioned developer sandboxes, clear policies, real-time coaching, and include active engineers in centres of AI excellence to convert unsanctioned experimentation into low-risk, measurable internal proofs of concept.
My Take:
This piece underscores a predictable but under-addressed fracture in enterprise security: engineers will build agentic automation when sanctioned tools and safe spaces are absent. In my consulting work I repeatedly see the same pattern — practical developer needs collide with restrictive policies, producing shadow experimentation that creates real business risk. My analysis of the article’s evidence (Anthropic Economic Index 2025, Netskope’s 5.5% finding, IBM’s 2025 breach costs) confirms the scale and immediacy of the problem. I’ve been highlighting that visibility, dev-centric sandboxes, and governance frameworks must be designed for practitioner workflows, not as top-down fiat. Practically, include active devs in Three Keystones governance, measure POC outcomes, and convert curiosity into controlled innovation.
5️⃣ When Hallucinations Cost Millions: CAIA Benchmark
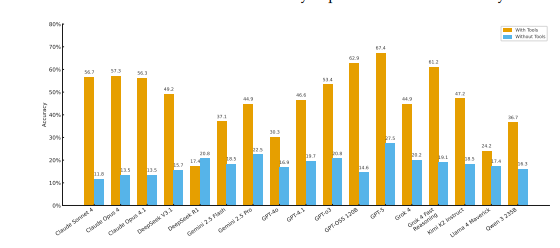
The paper introduces CAIA, an adversarial benchmark that evaluates 17 state-of-the-art AI models on 178 time-anchored financial decision tasks to expose catastrophic hallucinations and tool-misuse in high-stakes markets. Results show models without tools score 28% accuracy and tool-augmented agents plateau at 67.4% versus an 80% human baseline, while models systematically prefer unreliable web search over authoritative sources, creating irreversible financial risk.
Key Takeaways:
The authors build CAIA, an adversarial benchmark using crypto markets as a testbed and evaluate 17 models on 178 time-anchored tasks that require distinguishing truth from manipulation under irreversible financial decisions.
Models without external tools achieve only 28% accuracy, tool-augmented agents reach 67.4% but still lag an 80% human baseline, and models systematically prefer unreliable web search over authoritative data, exposing a tool selection catastrophe.
This exposes a foundational limitation for agentic AI in any adversarial domain — from cybersecurity to content moderation — making adversarial robustness, curated authoritative data, and controlled toolchains mandatory for enterprise autonomy.
My Take:
In my experience this paper validates a prediction I’ve been tracking: agentic systems fail less from lack of raw intelligence and more from poor instrument choice and governance in adversarial settings. CAIA maps cleanly to my SPAR framework — Sense the fragmented, time-anchored signals; Plan under adversarial incentives; Act with irreversible financial consequences; Reflect on catastrophic failure modes. Using the Three Keystones (Actions, Reasoning, Memory) the authors show reasoning scores alone are misleading without persistent memory and disciplined action-selection policies. Market-wise, as organizations position for a projected $10 trillion agentic AI market, this research signals a 2028 inflection where survivability under active deception becomes a procurement baseline. In my particular opinion, enterprise leaders should prioritize adversarial benchmarks, tool governance, and authoritative data feeds now; I find this pivot from accuracy to survivability will separate winners and losers in automation at scale.
What would you add to this conversation? Did we miss any important news this week? Your voice matters—let’s build the future together.
If you found this valuable, share it with your network. Because very soon, we won’t say, “There’s an app for that.” We’ll say, “There’s an agent for that.”
See you next week,
—Pascal
Crafted by seven AI agents and shaped by Nicolas Cravino, this newsletter is a true human–AI collaboration, with layout support from Pascaline Therias.
#AgenticAI #FutureOfWork #AIRevolution #Automation #AIagents